캐시 이해하기
한번 꺼내온 데이터 캐시에 저장해둬서 빠르게 다시 꺼내주기
쉽게 생각하면
캐시란 쉽게 생각하면 퀵슬롯처럼 한번 조회한 데이터의 사본을 밖에 가지고 있다가 다시 부르면 빠르게 사본을 주는 것이다.
사본?
주방을 예로 들어보자. 주방안에서 재료가 떨어져서 A메뉴가 주문불가 상태이다. 홀에서는 예상되는 메뉴의 사본인 메뉴판만 보고 주문을 하게되고 A메뉴를 return할 수 없게되어 문제가 발생한다. (가격이 변동됐다거나)
이는 주방과 홀 사이에 같은 정보를 토대로 사본으로 나눈 시점으로부터 데이터의 변경이 일어났음에도 즉시 반영이되지 않아 생긴일이다.
캐시도 원본 데이터의 복사본을 들고있기 때문에 빠른속도를 얻는 대신 정합성을 조심해야하는 기능은 것이다.
이러한 특징 때문에 원본 <-> 캐시데이터 간의 정합성을 맞춰주는 다양한 전략이 존재한다.
자세한 설명은 잘 정리된 링크로 대체한다.
[REDIS] 📚 캐시(Cache) 설계 전략 지침 💯 총정리
Redis - 캐시(Cache) 전략 캐싱 전략은 웹 서비스 환경에서 시스템 성능 향상을 기대할 수 있는 중요한 기술이다. 일반적으로 캐시(cache)는 메모리(RAM)를 사용하기 때문에 데이터베이스 보다 훨씬 빠
inpa.tistory.com
어떤 데이터를 캐싱하는 것이 좋을까?
위와 같은 특징으로 아래와 같은 데이터를 캐싱하는 것이 효과적이다.
- 잦은 조회가 발생
- 데이터의 변화가 적음
- 정합성이 맞지 않았음에도 치명적이지 않음
나의 리팩토링 방향
User객체, 유저정보를 캐시하려한다.
한번 가입하고 변경이 적은 편이고, 매 인증인가시에 select쿼리를 날려 가져와야하는 데이터이기 때문이다.
데이터 정합성의 경우 크리티컬한 필드는 USER에게 변경 권한을 주지않고 변경이 생겨도 닉네임정도이기에 진행하기로 했다.
아래는 우선 Quiz객체로 진행했지만 실제 서버에는 User로 적용하려한다.
글로벌캐시, 외부 Redis를 활용한다.
내부 서버의 로컬캐시를 활용하는 방향도 있겠지만 향후 확장을 고려하기도 하고 모든 DB서버를 따로 두고 있으므로 기존의 기조대로 우선 진행하려한다.
지금 토이프로젝트 단계에선 차이가 체감은 안되겠지만 향후 예상정도만 하고 선택하는 것에 의의를 뒀다.
Look Aside 패턴

주로 사용되는 전략이다.
Redis 서버가 다운되어도 DB서버에서 대체가 가능하고 (부하가 순간적으로 몰리긴 함),
한번 로그인한 사용자는 일정 기간동안 반복적으로 사용되므로 캐시에 적절한 TTL을 부여해 반복조회하려한다.
캐싱 적용하기
0. 의존성 추가
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.springframework.boot:spring-boot-starter-cache'
Spring에서 기본적으로 ConcurrentMapCache를 제공한다.
여기서 Spring Data Redis를 추가하면 자동으로 캐시가 RedisCache로 변경되는 점 참고하자.
1. @EnableCacheing 및 CacheConfig
@EnableCaching
@Configuration
public class CacheConfig {
@Bean
public RedisCacheConfiguration redisCacheConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(10))
.disableCachingNullValues()
.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())
)
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer())
);
}
}
2. @Cacheable, @CachePut, @CacheEvict 적용하기
캐시 데이터를 활용할 메소드에 어노테이션을 적용한다.

@Cacheable : 캐시 조회 (데이터가 없다면 생성 Look-Aside 전략)
@CachePut : 캐시 수정
@CacheEvict : 캐시 삭제
기본적으로 위와 같고 자세한 설명은 공식문서를 참조했다.
3. 적용 확인하기
퀴즈데이터 불러오기 전
현재 레디스 DB를 보면 Quiz 데이터는 없다.
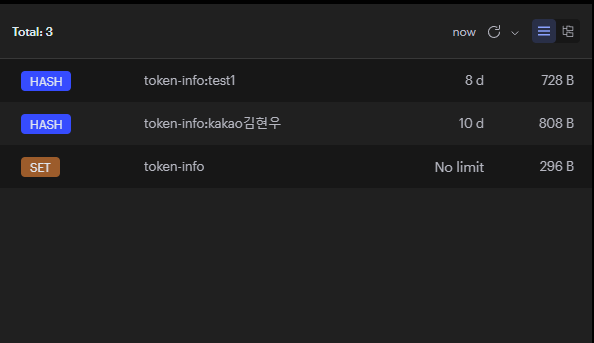
이 상태에서 조회하면 DB에서 가져오고 응답속도는 54ms가 나왔다.

캐시데이터 생성
레디스에 생성된 데이터를 확인할 수 있다.
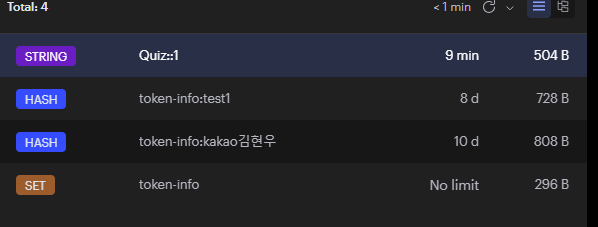

이후 데이터를 요청하면 응답속도가 7ms로 상당히 빨라진 것을 확인할 수 있다.

리팩토링 전/후 조회 속도 측정하기 (JMeter)
0. 테스트 환경
JMeter로 http 요청에 대한 응답을 측정했다.
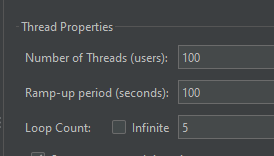
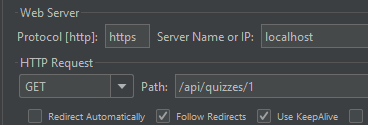
100명의 사용자를 가정하고 (쓰레드) 5번 반복, 총 500회의 요청을 날린다.
우선은 로컬환경을 기준으로 테스트하려한다.
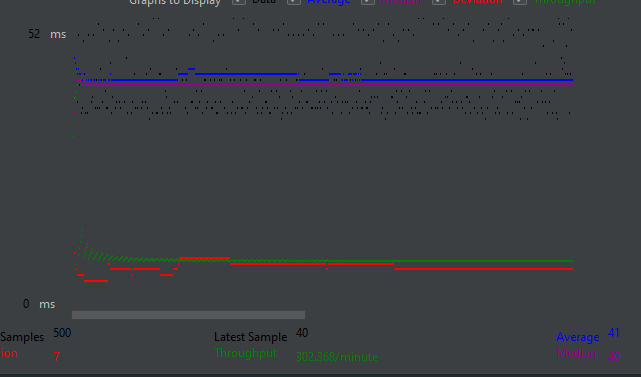
1. 기존 코드 테스트
측정 결과
평균 응답 속도 : 41ms

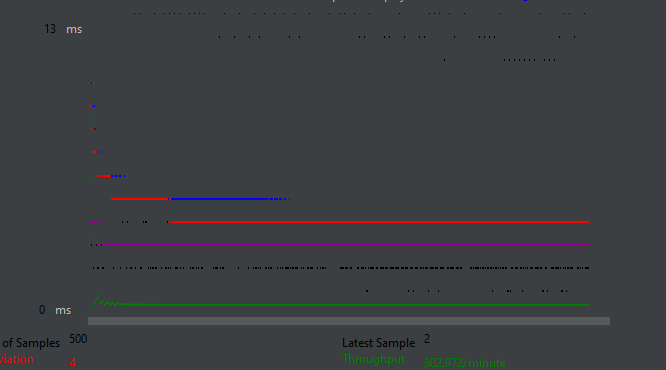
2. 캐싱적용 후 테스트
측정 결과
평균 응답 속도 : 4ms

3. 결과
[ 평균 응답속도 : 41ms -> 4ms ]
응답속도가 획기적으로 빨라진 것은 구조적으로 당연하다.
중요한 것은 이렇게 빠른 대신에 포기할 수 밖에 없는 동시성.
이를 잘 보완할 수 캐싱전략과 적절하게 캐싱시켜줄 케이스를 잘 판단해야하는 부분같다.
+추가 고민할 점

검은 점이 응답속도 결과 하나이다.
대부분은 아래에 찍혀있지만 중간중간 튀는 값들이 캐싱 전/후에 있다.
원인을 아직은 모르겠다...
트러블 슈팅
역직렬화 생성자 문제


기본 생성자가 존재하지 않아 역직렬화가 불가능하다고 확인된다.
시도 : 기본생성자 추가

결과 - 성공

LocalDateTime 직렬화 문제
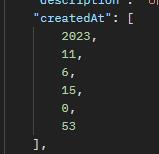
커스텀 모듈 추가로 해결.
블로그 작성중.
'Projects > 푸하하 - 개인 프로젝트' 카테고리의 다른 글
| [리팩토링] 작은 깨달음 : 리팩토링을 하기엔 데이터 수가 너무도 적었다 (0) | 2023.11.28 |
|---|---|
| [리팩토링] 레디스 캐싱을 통한 인증과정 유저정보 조회 속도 개선하기 (0) | 2023.11.28 |
| [테스트 코드] JaCoCo을 통한 코드 커버리지 확인 (1) | 2023.11.24 |
| [트러블 슈팅] github actions를 이용한 CD구현 도중 오류 (비공개 파일 포함해서 빌드하기, https) (1) | 2023.11.23 |
| [트러블] 쿠키 인식 오류. (다른 도메인 쿠키 접근 불가) (0) | 2023.11.20 |



