현재 상황
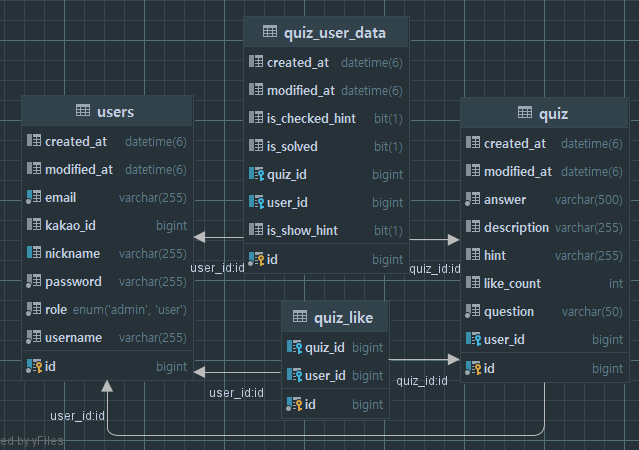
1. 퀴즈(Quiz)와 유저(User) 둘 다 외래키로 갖는 중간테이블인 두 객체 존재
quiz_like : 좋아요를 표시하기 위한 객체. 존재한다면 해당 유저가 해당 퀴즈를 좋아요 누른 것이다.
quiz_user_data : 특정 유저가 특정 퀴즈에 관련된 기록을 저장(퀴즈열람, 힌트열람, 정답).
2. 두번의 요청이 이루어지고 있다.


- 개발자 도구를 통해 위처럼 두번의 요청을 통해 따로 데이터를 받아오고 있는 것을 확인할 수 있다.
- 이 둘은 비동기적으로 동작한다.
- 각 559B, 598B 크기로 받아오고 있다.
- 거의 비슷하게 통신이 시작되어 각 68ms, 77ms 시간이 소요 됐다.
시도 : quiz_user_data로 like 데이터 통합하기
1. AS-IS
As-Is ) 좋아요 여부를 quiz_like 객체를 생성하고 삭제하여 데이터의 존재 유무로 판단
To-Be ) quiz_user_data의 is_liked의 값을 통해 좋아요 유무를 판단
MySQL을 이용하고 있다.
exist와 where의 성능의 차이가 곧 DB 성능으로 직결될 것으로 예상된다.
기존방식
like 여부 GET 요청 평균 : 45ms

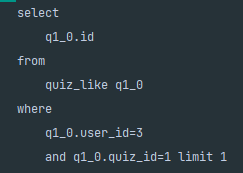
quiz_like 객체가 있는지 파악하는 쿼리가 발생한다.
아래 예시로 발생한 쿼리를 보면 user_id가 3이고 quiz_id가 1인 quiz_like 객체를 1개 select 한다.

quiz_user_data를 가져오는 GET 요청 : 평균 약 53ms


2. TO-BE
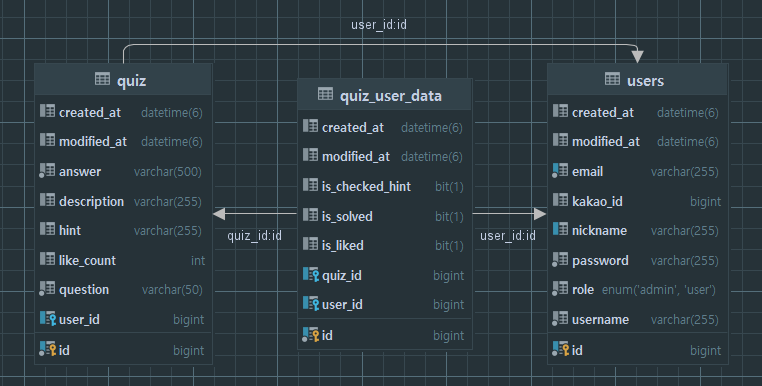
quiz_like를 삭제하고 quiz_user_data 테이블에 is_liked 칼럼을 추가했다.
해당 데이터가 1이라는 것은 해당 유저가 해당 퀴즈를 좋아요를 눌렀다는 의미이다.
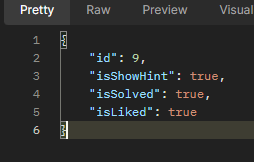
한번의 요청으로 좋아요 정보까지 가져온다.
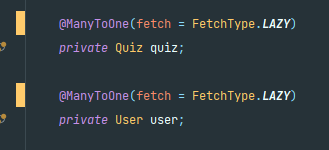
+ 응답속도가 약 53ms에서 41ms로 줄은 이유?
이전 쿼리에서 필요하지 않은 즉시 로딩이 일어나고 있었는데 이를 지연로딩으로 방지해주었다.
이로 인해 응답 속도가 줄은 것으로 예상된다.
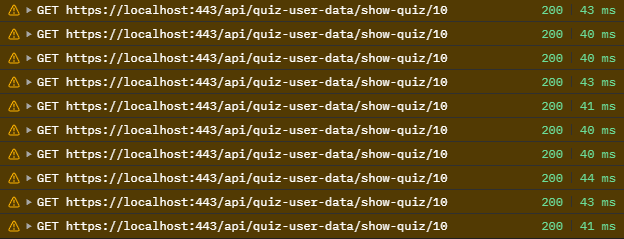
결과 : GET 요청 2회 -> 1회, 데이터 용량 약 52%로 감소
크롬 개발자 도구로 확인


두번의 요청에서 한번의 요청으로 바뀌었고, 데이터 용량은 598B + 559B 에서 613B로 줄었다. (52% 감소)
응답속도는 비동기로 처리되어 큰 차이가 없지만 요청한번을 줄여 서버 부하가 조금이나마 줄일 것으로 기대된다.
더 고민해볼 점
데이터 용량이 줄기야 했지만 나중에 해당 요청의 응답에 원하는 데이터가 변동되는 경우 어떤 것이 확장성이 좋을까?
아니면 확장될 여지가 적어 보이니 우선의 성능을 우선시 해야할까?
관련되어서 이미 현업의 개발자분들도 의견이 갈리는 부분인 것 같다.
이후 확장성을 위해서 굳이 요청을 나누는 경우도 있다하고, 아니기도 하고.
중요한 것은 각각의 장단점을 파악해 상황에 맞게 적용해보는 것이 아닐까 싶고,
우선은 각각의 경우의 특징을 숙지하는 것으로 일단락해보려 한다.
'Projects > 푸하하 - 개인 프로젝트' 카테고리의 다른 글
| [트러블 슈팅] QueryDsl 도입후 테스트시 빈생성 문제 (0) | 2023.12.04 |
|---|---|
| [리팩토링] QueryDSL 도입기 (0) | 2023.12.01 |
| [리팩토링] 작은 깨달음 : 리팩토링을 하기엔 데이터 수가 너무도 적었다 (0) | 2023.11.28 |
| [리팩토링] 레디스 캐싱을 통한 인증과정 유저정보 조회 속도 개선하기 (0) | 2023.11.28 |
| [리팩토링] Redis 캐싱을 통한 조회 성능 개선 도전기 (0) | 2023.11.28 |



