결록적으로 중복제거는 된다.
하지만, 그렇게 되면 Hash의 장점은 없이 LinkedList처럼 된다.
해쉬 충돌을 피하게 해줘야하는 이유와 비슷하다.
equals()를 재정의했다면 hashCode()도 같이 해주자.
코딩테스트 문제를 풀기 위해 자체 클래스 Path를 생성했다.
이 Path들의 객체를 중복없이 모은다음 개수를 리턴하기 위해 Set<Path>를 생성했고,
이를 위해 출발값과 도착값이 같으면 같은 객체로 인식하기 위한 일련의 과정을 정리했다.
0. 코드설명
Path 클래스
필드 : int[] from, int[] to
생성자 : 두 필드에 입력값을 받는 생성자만 존재 (from, to 에 null값이 존재하면 안되도록)
큰 값이 from에 오도록 정렬하여 생성. (방향만 다른 경우를 만들지 않게 하기 위해)
메소드 : Getter + toString, hashCode, equals 오버라이드
class Path {
private int[] from;
private int[] to;
Path(int[] from, int[] to) {
//from을 큰수의 배열로 지정 (앞자리수가 같으면 뒷자리수가 크게)
if( from[0] < to[0] || (from[0] >= to[0] && from[1] < to[1]) ) {
this.from = to;
this.to = from;
} else {
this.from = from;
this.to = to;
}
}
//Getter
public int[] getFrom() {
return this.from;
}
public int[] getTo() {
return this.to;
}
@Override
public String toString() {
return Arrays.toString(this.from) + " -> " + Arrays.toString(this.to);
}
@Override
public int hashCode() {
int result = Objects.hash(Arrays.hashCode(from));
result = 31 * result + Arrays.hashCode(to);
return result;
}
@Override
public boolean equals(Object obj) {
if(!(obj instanceof Path)) return false;
Path path = (Path) obj;
if( !Arrays.equals( this.from, path.getFrom() ) ) return false;
if( !Arrays.equals( this.to, path.getTo() ) ) return false;
return true;
}
}
1. Set<Path> 에 출발점과 도착점이 같은 객체를 중복 추가해보기
같은 필드값을 가지는 객체 생성 후 Set.add를 해주면 결과가 어떨까?
hashCode() 결과값이 같은 경우, 다른 경우를 비교해서 아래 코드의 동작 결과를 알아보자
//객체생성
Path p1 = new Path(new int[]{1,2}, new int[]{1,0});
Path p2 = new Path(new int[]{1,2}, new int[]{1,0});
//Set생성 및 객체 추가
Set<Path> set = new HashSet<>();
set.add(p1);
set.add(p2);
System.out.println(set);
A. 고의로 Path가 모든 객체가 같은 hashCode()의 결과값이 나온다면?
@Override
public int hashCode() {
System.out.println("hashcode 체크");
return 1; // -> 고정된 값 리턴
}
@Override
public boolean equals(Object obj) {
System.out.println("equals 체크");
if(!(obj instanceof Path)) return false;
Path path = (Path) obj;
if( !Arrays.equals( this.from, path.getFrom() ) ) return false;
if( !Arrays.equals( this.to, path.getTo() ) ) return false;
return true;
}위와 같이 고의로 고정된 hashCode()의 리턴값을 보내주게 한 상태로 같은 필드값을 갖는 객체를 두번 add 해줘보았다.
결과

첫번째 hashcode 체크 : 처음 add가 실행될때 동작.
두번째 hashcode 체크 : 두번째 add가 실행될때 동작.
equals 체크 : 두번째 add에서 해시값이 같아서 실제로 같은 값인지 체크하기 위해 동작
set출력 : 결과적으로 중복 없이 등록되었다.
여기서 중복이 해결됐으니, 'hashCode()결과값이 같아도 크게 문제가 없지 않은가?'
라고 순수하게 생각이 들 수 있다.
2. HashSet은 add할때 객체가 중복된 객체인지 어떻게 판별할까
중복된 객체를 어떻게 판별하는지 우선 HashMap의 소스코드를 확인해보자.

참고로, HashSet은 HashMap을 기반으로 동작하며, 값에 더미데이터를 넣어주고 오직 키값만 활용한다.

map.put의 메소드를 찾아가보자.

putVal 메소드로 연결해주고 있다.
여기서 첫번째 파라미터로 hash(key)를 전달하고 있는데, hash() 메소드를 확인해보자.

여기서 hash값을 가져올때 해당 객체의 hashCode()메소드가 동작한다.
결과적으로, putVal메소드의 첫번째 파라미터에 들어가는 hash(key)의 값은 항상 고정될 것이다.
(여기서 K는 Path클래스이며 hash메소드에서 호출되는 key.hashCode()값이 고정되어 있기 때문)
> putVal() 메소드를 살펴보자
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 해시테이블 초기화
// (생략)
// 해시값을 통해서 도출된 인덱스값으로 해시테이블(배열)의 값이 있는 지 체크
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 해시값에 이미 값이 존재하는 경우
else {
Node<K,V> e; K k;
// 해시값이 같고, 키 값도 같은 경우 -> 덮어쓰기
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 해시충돌 : 해시값은 같지만, 키 값은 다른 경우
else {
for (int binCount = 0; ; ++binCount) {
// Node의 next를 계속 타고타고 들어가서 LinkedList의 형태를 띈다
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
...
return oldValue;
}
}
...
}
결과적으로, 같은 키값인지 hashCode( ) 값을 기반으로 1차 검증 후, Equals( ) 를 통해 같은 객체인지 판별한다.
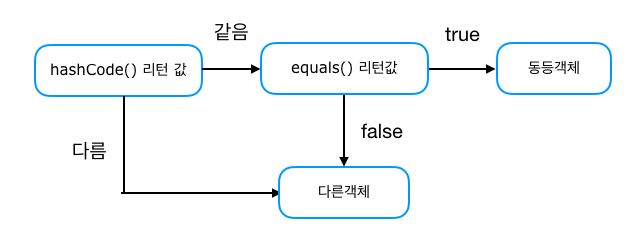
3. 그럼 결과적으로 같은 해쉬의 다른 객체들이 쌓이면 무슨 문제가 발생할까?
//필드값이 다른 객체생성
Path p1 = new Path(new int[]{1,2}, new int[]{1,0});
Path p2 = new Path(new int[]{2,7}, new int[]{2,6});
//Set생성 및 객체 추가
Set<Path> set = new HashSet<>();
set.add(p1);
set.add(p2);
System.out.println(set);
필드값이 다른 경우 HashSet에 추가해보면?

당연하게도 중복없이 두개의 객체가 Set에 들어온다.
하지만 여기서 주목해야할 것은 'equals체크'이다.
임의로 해시값을 고정값으로 했기에 equals() 가 false임에도 해시충돌이 발생했다는 것을 의미한다.
그리고 이러한 방식은 LinkedList의 형태로 저장이 되기에 성능에 좋지 못하다.
(현재는 특정 뎁스 이후로는 트리형태로 변환된다)
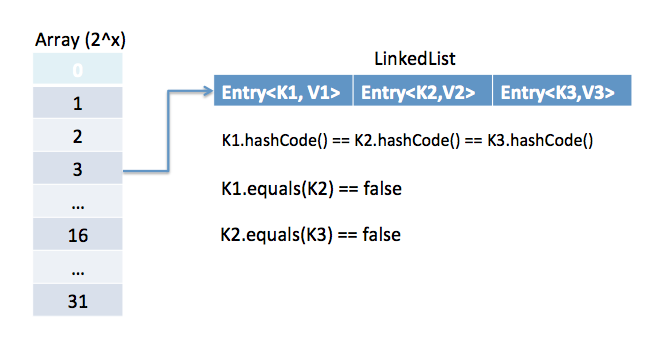
결론
Hash개념을 몰랐다면 이 질문에 답할 수 없을 것이다.
hashCode()를 잘 재정의해주는 것이 객체의 동등 비교를 위해 중요하다.
특히나 Hash를 활용한 컬렉션을 사용할 때는 더더욱.
'해시를 잘 짜면..' 라고 했던 말들이 이러한 점들을 포함하는 것인가 생각해보게 됐다.
'Back-End > Java' 카테고리의 다른 글
| List객체를 toString()하게 되면 일어나는 일 (1) | 2024.09.04 |
|---|---|
| TIL 230712 : 자바의 람다식 짚고 넘어가기(2) 메소드 참조 (0) | 2023.07.13 |
| TIL 230711 : 자바의 람다식 짚고 넘어가기. (0) | 2023.07.12 |
| TIL 230614 : 실행은 같아도 코드는 다르다. (0) | 2023.06.19 |
| TIL 230612 : 날짜 시간 데이터와 인사하기. (2. SimpleDateFormat) (0) | 2023.06.12 |

